centos 7 galera node recovery hang in CC

Hello everybody!
I am having some trouble here with latest clustercotnrol 1.2.11 with centos7.
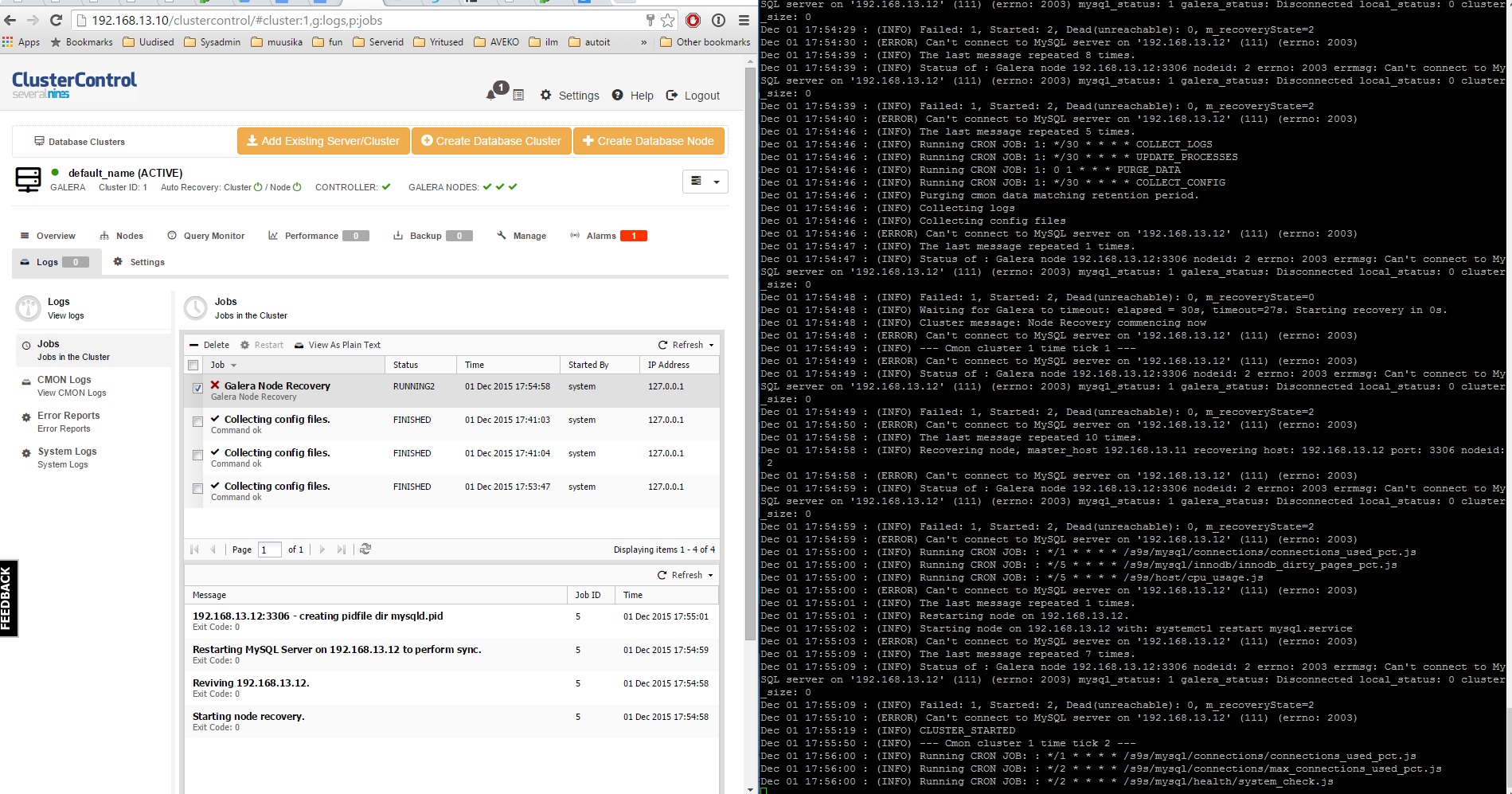
After rebooting one server, clustercontrol starts recovery Job and the node gets back online.
Problem is that in Clustercontrol Job list it never finishes, although the node is online.
Last message is creating pidfile dir mysqld.pid. I can see the file been created to /root/mysqld.pid ,
no permission errors.
Also when trying to reboot another node it will not recover cause the last job is still processing.
Have tried many clean installs but always the same.
Restarting cmon seems to clear the pending job
This is very strange problem and have never encountered it with centos 6 version. Any suggestions what
to try would be really helpful. Have attached a picture of the problem.
centos7cc.jpg
-
Hi again!
Here is information about version:
Database Version 5.6.26-74.0-56(Percona XtraDB Cluster (GPL), Release rel74.0, Revision 1, WSREP version 25.12, wsrep_25.12) Vendor: percona ClusterControl UI version: 1.2.11.f197b79 ClusterControl CMON Version: 1.2.11.1023 CMON API Version: 1.2.11.4f43a28 OS: redhat [root@workroom-db2 ~]# ps -ef | grep -i mysql
root 5125 4944 0 22:35 ? 00:00:00 systemctl restart mysql.service
root 5151 1 0 22:35 ? 00:00:00 /bin/sh /usr/bin/mysqld_safe --basedir=/usr
root 5153 1 0 22:35 ? 00:00:00 /bin/bash -ue /usr/bin/mysql-systemd start-post 5151
mysql 6066 5151 1 22:35 ? 00:00:03 /usr/sbin/mysqld --basedir=/usr --datadir=/var/lib/mysql --plugin-dir=/usr/lib64/mysql/plugin --user=mysql --wsrep-provider=/usr/lib64/libgalera_smm.so --log-error=/var/log/mysqld.log --pid-file=/var/lib/mysql/mysqld.pid --socket=/var/lib/mysql/mysql.sock --port=3306 --wsrep_start_position=e13bbc40-9930-11e5-a777-46994f0fe596:13
root 54926 3351 0 22:41 pts/0 00:00:00 grep --color=auto -i mysqlJust did another clean install of Centos 7 servers and new CC deployment (http://severalnines.com/New-Galera-Configurator/ - RHEL7) but exactly the same problem. Could it be systemctl related problem? I can see that the process "systemctl restart mysql.service" is not finishing, although mysql is started correctly and cluster is synced. I have attached photo of logs. Tried manually command systemctl restart mysql.service and it seems to get stuck.
Best regards,
Rene
-
Here is information about systemd status mysql:
[root@workroom-db3 ~]# systemctl status mysql -l
mysql.service - Percona XtraDB Cluster
Loaded: loaded (/usr/lib/systemd/system/mysql.service; enabled)
Active: activating (start-post) since Wed 2015-12-02 22:56:24 EET; 15min ago
Process: 56225 ExecStopPost=/usr/bin/mysql-systemd stop-post (code=exited, status=0/SUCCESS)
Process: 56239 ExecStartPre=/usr/bin/mysql-systemd start-pre (code=exited, status=0/SUCCESS)
Main PID: 56263 (mysqld_safe); : 56264 (mysql-systemd)
CGroup: /system.slice/mysql.service
├─56263 /bin/sh /usr/bin/mysqld_safe --basedir=/usr
├─57177 /usr/sbin/mysqld --basedir=/usr --datadir=/var/lib/mysql --plugin-dir=/usr/lib64/mysql/plugin --user=mysql --wsrep-provider=/usr/lib64/libgalera_smm.so --log-error=/var/log/mysqld.log --pid-file=/var/lib/mysql/mysqld.pid --socket=/var/lib/mysql/mysql.sock --port=3306 --wsrep_start_position=e13bbc40-9930-11e5-a777-46994f0fe596:13
└─control
├─56264 /bin/bash -ue /usr/bin/mysql-systemd start-post 56263
└─65081 sleep 1Dec 02 22:56:24 workroom-db3 mysql-systemd[56239]: /usr/bin/mysql-systemd: line 31: [: too many arguments
Dec 02 22:56:24 workroom-db3 mysql-systemd[56239]: /usr/bin/mysql-systemd: line 39: [: too many arguments
Dec 02 22:56:24 workroom-db3 mysql-systemd[56239]: /usr/bin/mysql-systemd: line 45: [: /var/log/mysqld.log: binary operator expected
Dec 02 22:56:25 workroom-db3 mysqld_safe[56263]: 151202 22:56:25 mysqld_safe Logging to '/var/log/mysqld.log'.
Dec 02 22:56:25 workroom-db3 mysqld_safe[56263]: 151202 22:56:25 mysqld_safe Starting mysqld daemon with databases from /var/lib/mysql
Dec 02 22:56:25 workroom-db3 mysqld_safe[56263]: 151202 22:56:25 mysqld_safe Skipping wsrep-recover for e13bbc40-9930-11e5-a777-46994f0fe596:13 pair
Dec 02 22:56:25 workroom-db3 mysqld_safe[56263]: 151202 22:56:25 mysqld_safe Assigning e13bbc40-9930-11e5-a777-46994f0fe596:13 to wsrep_start_position
[root@workroom-db3 ~]# -
OK, I finally figured it out. Firewall was not affecting the problem.
Solution was making changes to default my.cnf files on nodes:
[MYSQLD]
commented out:
#pid_file=mysqld.pid
#log_error=/var/log/mysqld.log
under [MYSQLD_SAFE]
commented out:
#datadir=/var/lib/mysql
Seems to be some conflict with systemd and my.cnf (don't like double definations? )
so datadir is defined under [MYSQLD] and log+pid under [MYSQLD_SAFE]
Now systemctl restart mysql.service works and all nodes recover automatically.
Before these changes systemctl showed error:
Dec 02 22:56:24 workroom-db3 mysql-systemd[56239]: /usr/bin/mysql-systemd: line 31: [: too many arguments
After changes error is gone and service started. All data nodes recover automatically :)
Best regards,
Rene

{kind=link}
Please sign in to leave a comment.
Comments
5 comments